Looking around at Python data science packages, I first started with Spyder. It was capable, but it was a bit unpolished, so I kept looking and found Jupyter and the new Jupyter Lab project, which, while in active development, looks like it might be a good fit for my project.
In this guide I will guide you through creating a user-space Anaconda environment, install Jupyter Lab, and create a systemd service that will automatically run Jupyter Lab at startup. I did everything in an Ubuntu 17.04 Server (headless) virtual machine running in VMWare Workstation 14 on Windows 10, although this should work for any Linux distribution with systemd.
![]()
Step 1: Set Up Your Environment
Install Pyenv
Pyenv is a fantastic script that will manage your python environment so you don’t have to worry about changing the system default python environment.
Pyenv Prerequisites
You need a system with certain build packages installed already - so if you don’t have root access, talk to your sysadmin to get these installed. Chances are they already are.
$ sudo apt install -y make build-essential libssl-dev zlib1g-dev libbz2-dev \
libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev libncursesw5-dev \
xz-utils tk-dev
With these installed, you’re ready to install pyenv.
The simplest way to install pyenv is through pyenv installer, with the following commands:
$ curl -L https://raw.githubusercontent.com/pyenv/pyenv-installer/master/bin/pyenv-installer | bash
The installer will spit out a blob of code it thinks you should put in your ~/.bash_profile file, something like this:
export PATH="~/.pyenv/bin:$PATH"
eval "$(pyenv init -)"
eval "$(pyenv virtualenv-init -)"
Update pyenv with this command:
$ pyenv update
If you get a command not found error, you may need to reload your ~/.bash_profile so your current shell session knows where the pyenv command is:
$ source ~/.bash_profile
You now have a working pyenv environment.
Install Anaconda
Pyenv is great because you can install many versions of Python, or Python distributions such as Anaconda or Miniconda.
To see a list of the available distributions, type
$ pyenv install -l
Jupyter is part of Anaconda, so we’ll install the current (as of this guide) release of Anaconda:
$ pyenv install anaconda3-5.0.1
This step will take some time, since Anaconda is a hefty distribution.
Once Anaconda is installed, activate it with the activate subcommand. Pyenv supports tab completion which makes many commands easier:
$ pyenv activate ana<tab key>
$ pyenv activate anaconda3-5.0.1
(anaconda3-5.0.1) $
You may also deactivate the current pyenv with the command
(anaconda3-5.0.1) $ pyenv deactivate
$
Install Node.js
We need Node.js for the Jupyter Lab plugins, and we can install that to our user profile as well with Node Version Manager (NVM).
To install nvm, use the following command:
curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.33.8/install.sh | bash
nvm automatically adds the proper environmental variables to your ~/.bashrc file, but let’s move it to your ~/.bash_profile. Edit ~/.bashrc with your editor of choice, and look for the following lines (close to the end):
export NVM_DIR="$HOME/.nvm"
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm
[ -s "$NVM_DIR/bash_completion" ] && \. "$NVM_DIR/bash_completion" # This loads nvm bash_completion
Cut them from ~/.bashrc and paste them into ~/.bash_profile
You won’t have access to nvm until you either log out or reload ~/.bash_profle with
$ source ~/.bash_profile
Now that we have nvm installed, let’s install node.js. To see a list of available node.js distributions available, type
$ nvm ls-remote
To install the most current LTS release of node.js, type
$ nvm install --lts
Now we have an environment ready for Jupyter Lab.
Step 2: Install & Configure Jupyter Lab
Install Jupyter Lab
Installing Jupyter Lab is as simple as a single conda command from the Anaconda environment:
$ pyenv activate anaconda3-5.0.1
(anaconda3-5.0.1) $ conda install -c conda-forge jupyterlab
The script will ask you to upgrade (or downgrade) certain modules to accomodate jupyterlab.
Once it is installed, test that it works with the command
(anaconda3-5.0.1) $ jupyter lab
...<logs>...
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://localhost:8888/?token=1ba6d4c77e6b6028365e2467f5134ce128f5d3a649aa2a26
If your command was successful, you’ll see output like that above, with a link and token. If you are running jupyterlab on a different machine, you won’t be able to access it since it is not listening to external requests (only localhost by default).
Configure Jupyter Lab
Configuring jupyterlab isn’t very straightforward since the documentation is pretty sparse. Much of the documentation for jupyter notebook applies to jupyterlab, however.
Listen on an external IP address
The --ip argument specifies which IP address to listen for connection requests on, so determine your ip address with ip address command
--ip=<your ip address>
Enable SSL
If you want to enable SSL, follow these steps as well, pulled from the Jupyter Notebook docs.
Make a directory to store your keys and self-signed cert. I created mine in ~/.jupyter, which is the default jupyterlab config directory (use the command (anaconda3-5.0.1) $ jupyter --config-dir to see yours). Once you have a directory for your keys and cert, use the following command to generate them:
(anaconda3-5.0.1) $ mkdir -p ~/.jupyter/keys
(anaconda3-5.0.1) $ cd ~/.jupyter/keys
(anaconda3-5.0.1) $ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout mykey.key -out mycert.pem
Now, we use the command line parameters --keyfile and --certfile to use when setting up our jupyterlab server:
--keyfile=~/.jupyter/keys/mykey.key
--certfile=~/.jupyter/keys/mycert.pem
Test Parameters
Now we can test these parameters to make sure they work, and we can access Jupyter Lab from an external browser:
(anaconda3-5.0.1) $ jupyter lab --ip=<your ip address> --keyfile=~/.jupyter/keys/mykey.key --certfile=~/.jupyter/keys/mycert.pem
...<logs>...
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
https://<your ip address>:8888/?token=35b5492a621e16fdcc97c0a9d7e3c4241416737ca8e7f0fd
You should now be able to access that URL and access Jupyter Lab.
You may have to click through self-signed cert warnings in your browser. The Jupyter Notebook docs have instructions on how to get trusted SSL certs as well.
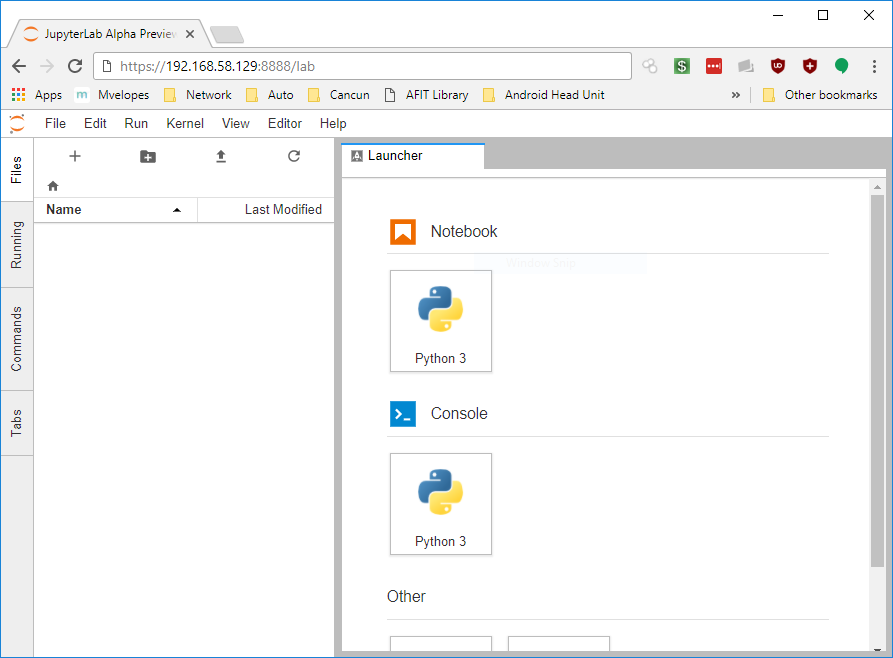
Step 3: Running Jupyter Lab as a User Service
There are certain advantages to creating your environment using pyenv and nvm, however running services as a user is a little tricky.
The first step is to create and modify a Jupyter Notebook config file. I assume that since Jupyter Lab is beta, it will eventually have its own config file, but for now it uses the Notebook config.
jupyter_notebook_config.py
Initialize a Jupyter Notebook config file with the command
(anaconda3-5.0.1) $ jupyter lab --generate-config
You now have a file called jupyter_notebook_config.py in your jupyter config directory (most likely ~/.jupyter). Edit that file, and let’s place some of your command line arguments there instead. Modify the following lines
#c.NotebookApp.keyfile = ''
#c.NotebookApp.certfile = ''
to
c.NotebookApp.keyfile = '/home/<YOUR USER>/.jupyter/keys/mykey.key'
c.NotebookApp.certfile = '/home/<YOUR USER>/.jupyter/keys/mycert.pem'
You must use absolute paths here, since a home path with ~ doesn’t work in our script below.
You may specify your ip address in this config file (by uncommenting and modifying #c.NotebookApp.ip = 'localhost'), however if your environment has dynamic ip addresses, you can dynamically determine your ip address in the startup script below.
Enable Password Login
If you want to log in using a password, use the following command to generate a password in your config file:
(anaconda3-5.0.1) $ jupyter notebook password
Enter password: ****
Verify password: ****
[NotebookPasswordApp] Wrote hashed password to ~/.jupyter/jupyter_notebook_config.json
You will now be prompted for a password instead of required to use the generated token.
jupyterlab.sh
Create a file called jupyterlab.sh in your home directory (or anywhere else), and open it up in your favorite text editor.
#!/bin/bash
eval "$(pyenv init -)"
pyenv activate anaconda3-5.0.1
cd <your jupyterlab working directory>
IP=`ip -4 route get 8.8.8.8 | awk {'print $7'} | tr -d '\n'`
jupyter lab --no-browser --ip=$IP
Modify the 4th line above (cd) to change directory to your data working directory.
Line 5 will start jupyterlab on the current ip address that is routable to the internet. You can change this or remove this and statically set the ip addres as well.
Save the file and chmod it to allow execution:
(anaconda3-5.0.1) $ chmod +x jupyterlab.sh
You may test this script by running the script (in or out of the anaconda environment):
$ ./jupyterlab.sh
Create Jupyter Lab startup script
Now that we have a working jupyterlab startup script, we can create a user service for it. I use systemd for this.
First, create the directory systemd looks in for user-defined services:
$ mkdir -p ~/.config/systemd/user/
Edit the file ~/.config/systemd/user/jupyterlab.service to look like this:
[Unit]
Description=Service to run JupyterLab in user space
[Service]
ExecStart=/bin/bash -c "source ~/.bash_profile; eval ~/jupyterlab.sh"
[Install]
WantedBy=default.target
Now enable the jupyterlab.service you just created with
$ systemctl --user enable jupyterlab.service
If you get a message like Failed to connect to bus: No such file or directory, it means the dbus service isn’t running for your user. Restarting, or starting a new shell should do the trick. I had this issue when logging in as a new user using the su - <user name> command.
Start the service with the start command, and view the status of the service with the status command:
$ systemctl --user start jupyterlab
$ systemctl --user status jupyterlab
If you don’t see any log messages when using the status command, you may need to edit /etc/systemd/journald.conf as root and set the value Storage=persistent, per this issue
The output from status will tell you the address to visit and help you with troubleshooting steps as well. If you still are using tokens (instead of a password, as described above), the token will be displayed in this log.
That’s it! You now have a service that automatically starts that will give you remote access to Jupyter Lab.
Bonus - Jupyter Lab Widget Support
To enable ipywidgets widget support with jupyterlab, run the following command from your anaconda environment:
(anaconda3-5.0.1) $ conda install -c conda-forge ipywidgets
(anaconda3-5.0.1) $ jupyter labextension install @jupyter-widgets/jupyterlab-manager
![]()
![]()
![]()
 Image Credit: Ethereum Group
Image Credit: Ethereum Group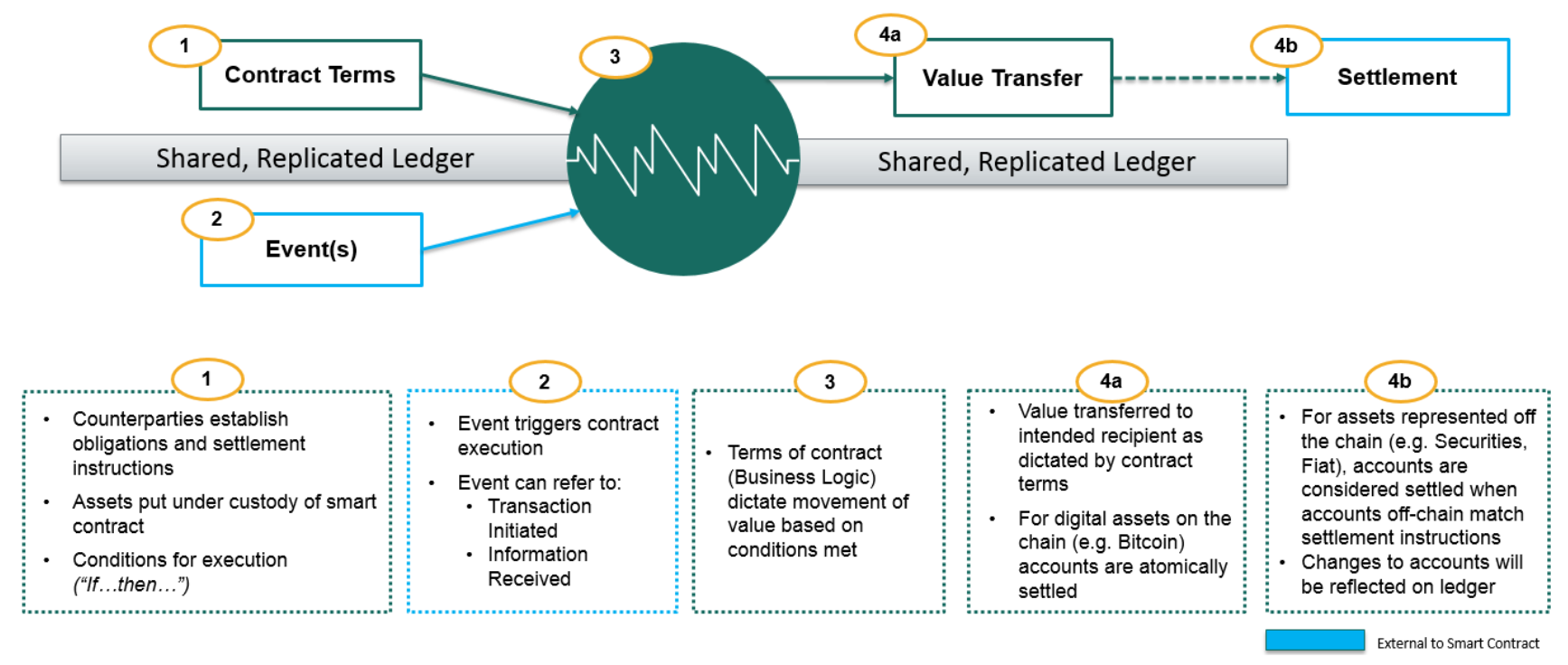 Figure 1 - Smart Contract; Image credit: Jo Lang / R3 CEV
Figure 1 - Smart Contract; Image credit: Jo Lang / R3 CEV Figure 2 - Deep Thought; Image credit: Hitchhiker’s Guide to the Galaxy
Figure 2 - Deep Thought; Image credit: Hitchhiker’s Guide to the Galaxy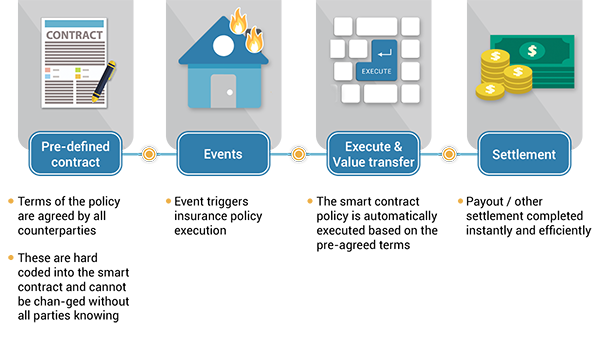 Figure 3 - Smart Contract Example for Insurance; Image Credit: Wikipedia
Figure 3 - Smart Contract Example for Insurance; Image Credit: Wikipedia Image credit: The Linux Foundation
Image credit: The Linux Foundation
 Image credit: Sovrin Foundation
Image credit: Sovrin Foundation

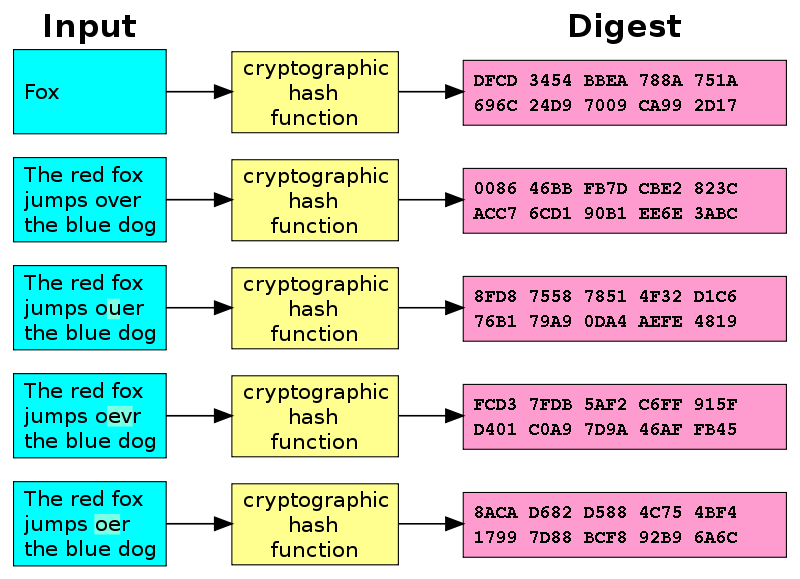 Figure 1 - Hash Diagram (Image credit: Wikipedia)
Figure 1 - Hash Diagram (Image credit: Wikipedia)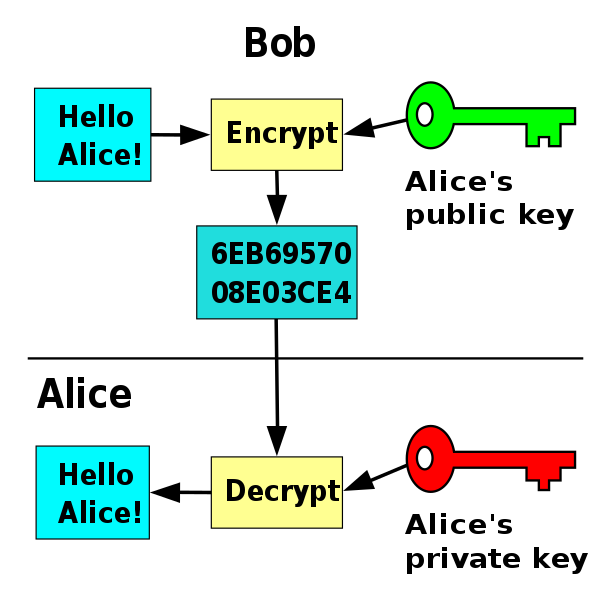 Figure 2 - Public Key Flowchart (Image credit: Wikipedia)
Figure 2 - Public Key Flowchart (Image credit: Wikipedia)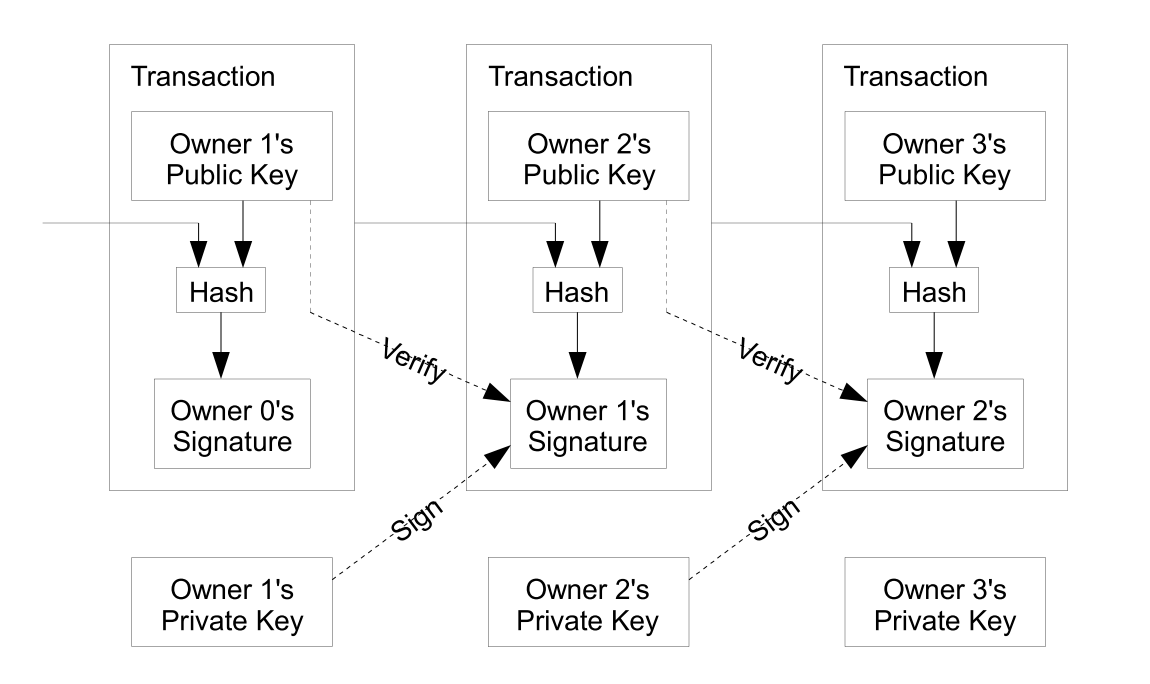 Figure 3 - Bitcoin Transactions (Image credit: Satoshi Nakamoto)
Figure 3 - Bitcoin Transactions (Image credit: Satoshi Nakamoto)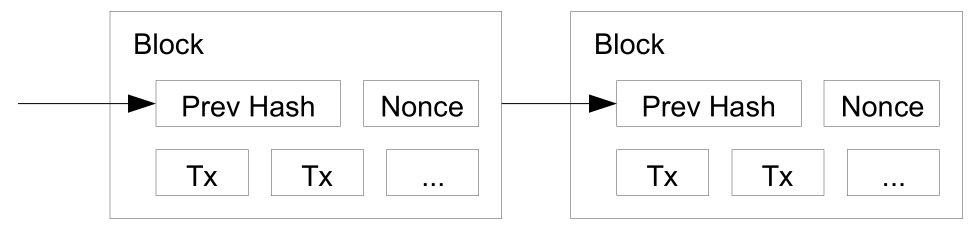 Figure 4 - Blockchain (Credit: Satoshi Nakamoto)
Figure 4 - Blockchain (Credit: Satoshi Nakamoto)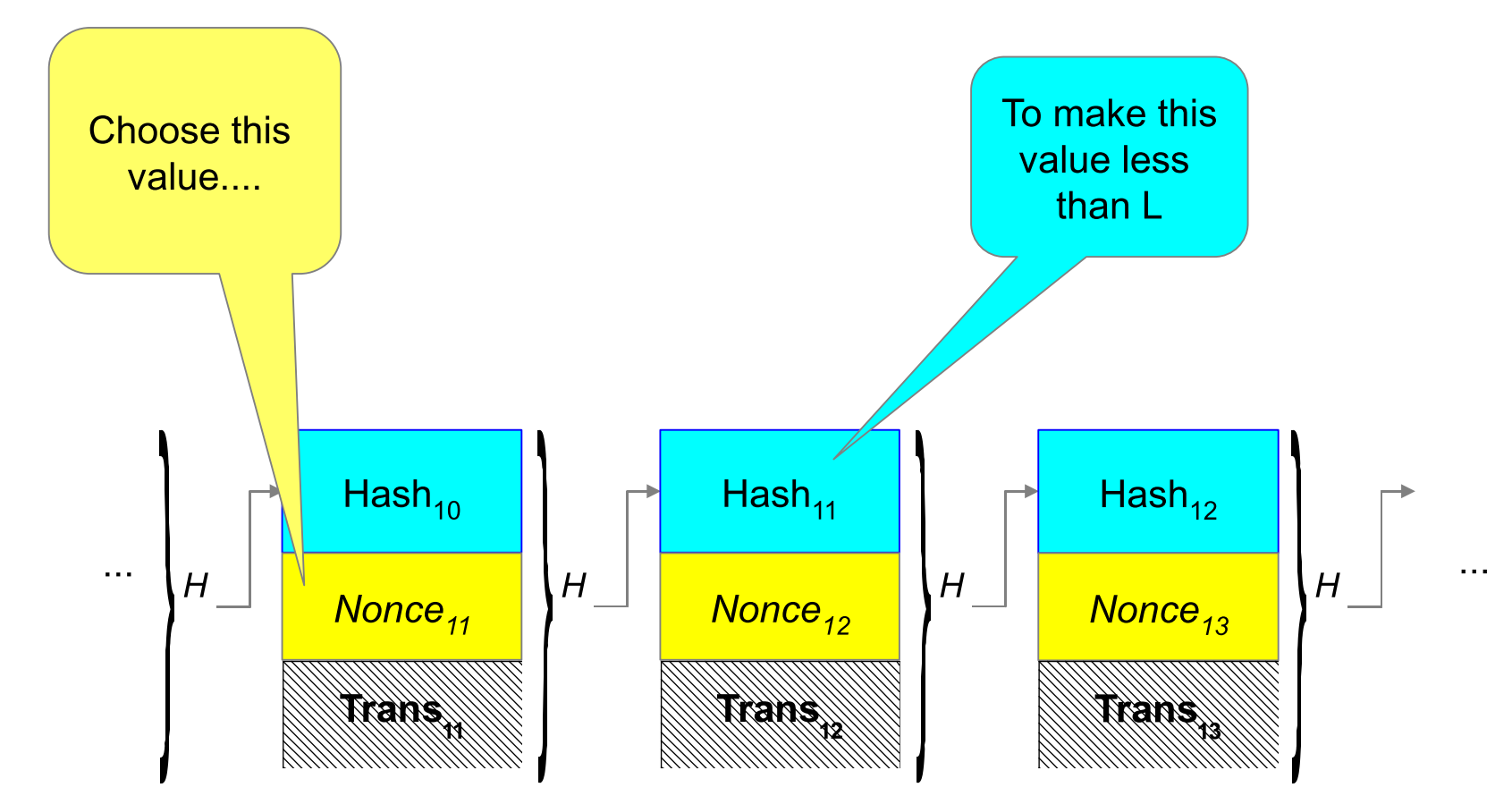 Figure 5 - Proof of Work; Image credit: John Kelsey, NIST
Figure 5 - Proof of Work; Image credit: John Kelsey, NIST Image credit: Zoolander
Image credit: Zoolander
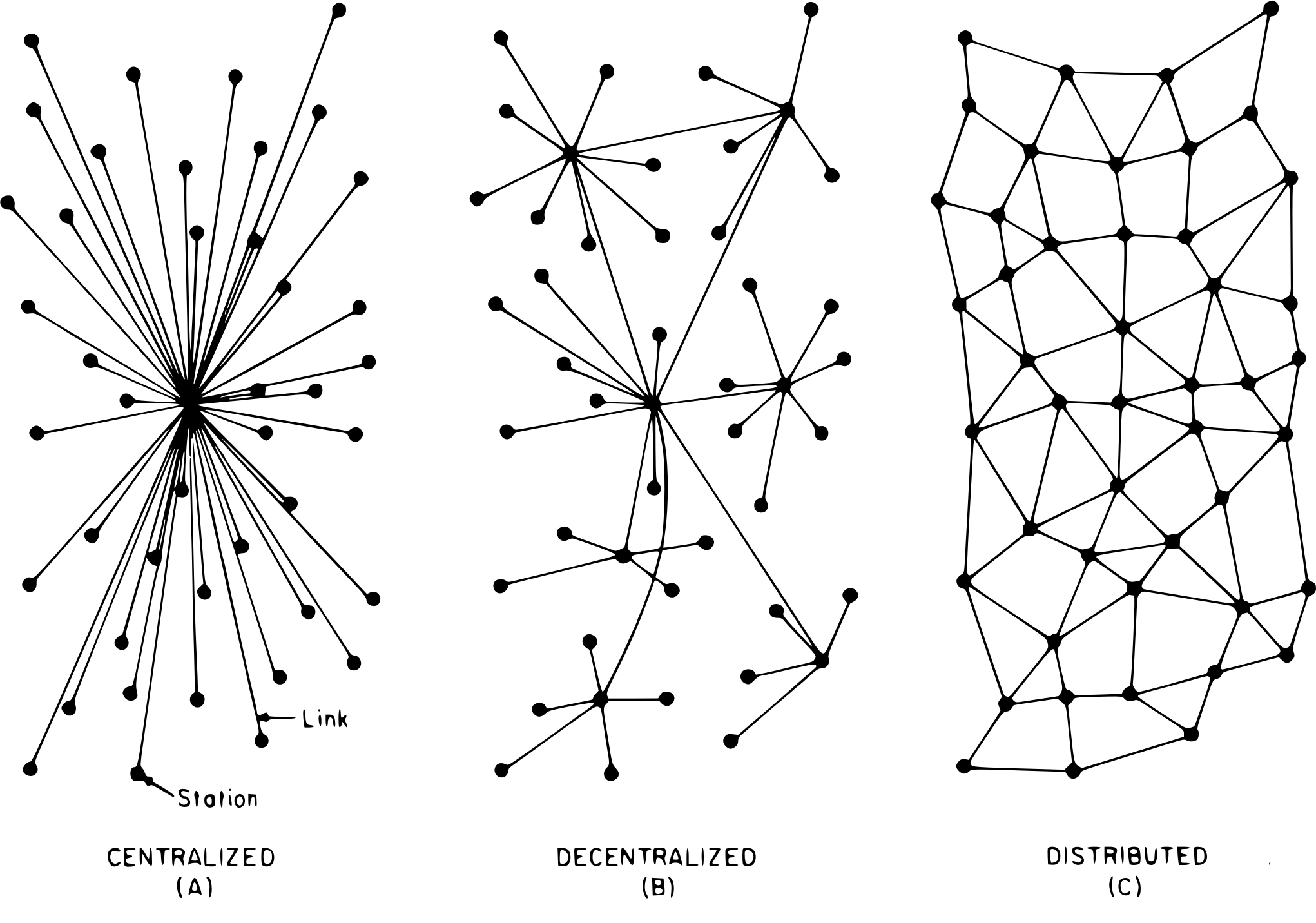 Figure 1 - Network Types (Image credit: Wikipedia)
Figure 1 - Network Types (Image credit: Wikipedia)
